Methodology
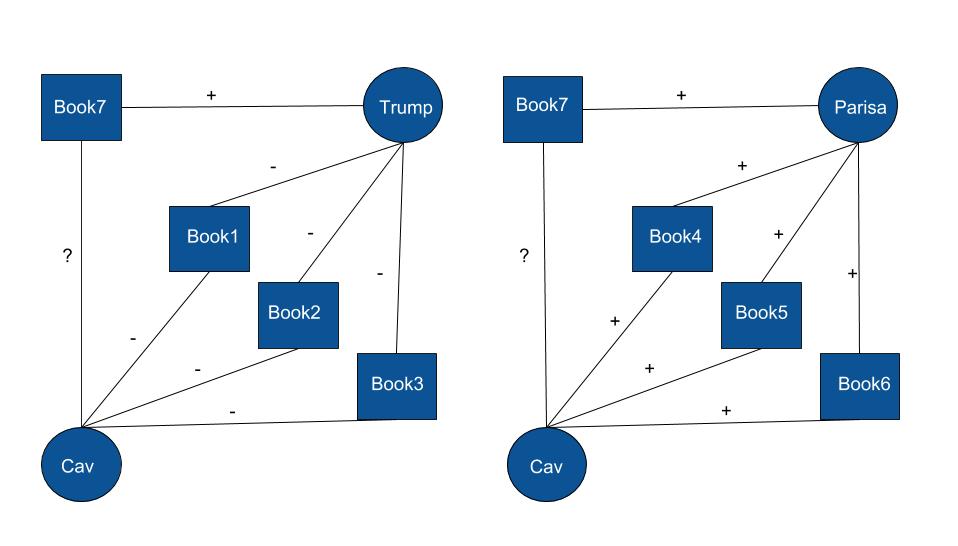
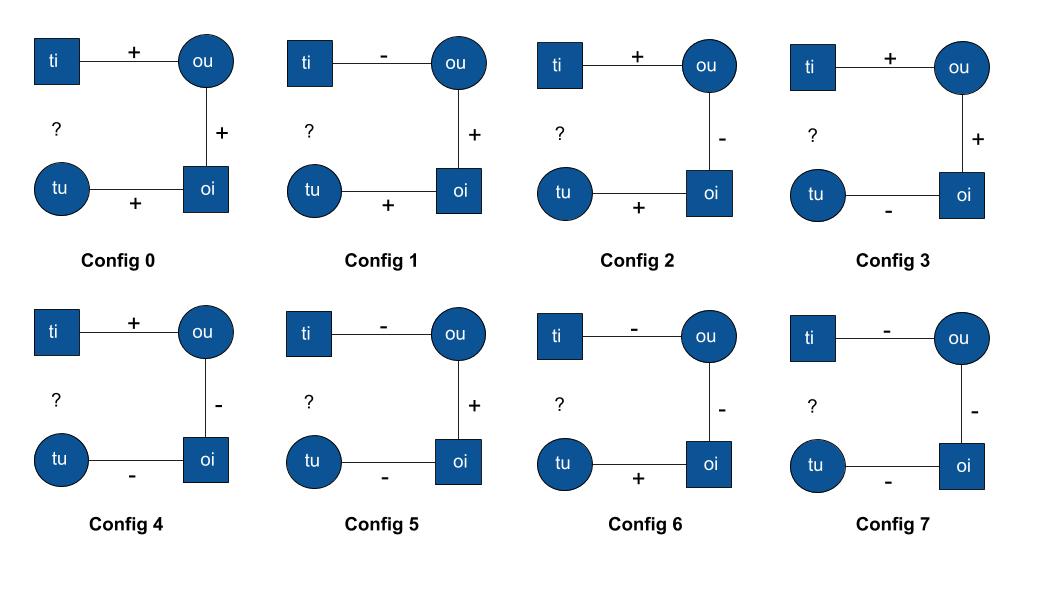
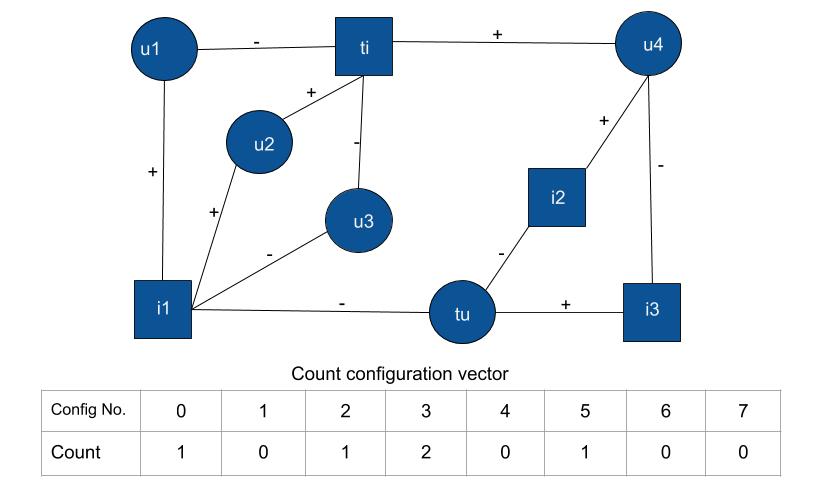
To take advantage of the dislikes of the user, we plan to use the method of 'Love-Hate Square Counting Method' proposed in [1] Let's take an example to explain this! Suppose Cav is friends with Trump and Parisa. Now, Cav hates 3 books which Trump also hates & Cav loves 3 books which Parisa also loves. Now if we know that Trump likes "Twilight" and Parisa likes "Life of Pie", then , is it more likely for Cav to like "Twilight" or "Life of Pie"? This is exactly the question we are trying to answer with BookLook!